新智元报道
编辑:编辑部 HNZ
【新智元导读】由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!
就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!
这一成就,再次让AI社区轰动。
博客地址:https://turningpointai.notion.site/the-multimodal-aha-moment-on-2b-model
开源项目:https://github.com/turningpoint-ai/VisualThinker-R1-Zero
DeepSeek-R1的独特推理能力,能成功扩展到多模态推理领域吗?
UCLA等机构的研究者发现,虽然目前已经涌现出许多试图复现DeepSeek-R1的研究,然而这些研究大多遭遇了这个难点:很难复现出R1所表现出的回答长度增加和思考模式。
幸运的是,他们成功了!如同DeepSeek-R1论文所描述的那样,多模态的「啊哈时刻」出现了——模型回答中涌现出了自我反思能力。
他们不仅成为全球首个成功在多模态推理中产生了「啊哈时刻」涌现现象和回答长度增加的团队,而且仅仅使用了一个未经监督微调的2B模型。
此外他们还发现:更长的推理过程可以让以视觉为中心的任务极大受益。
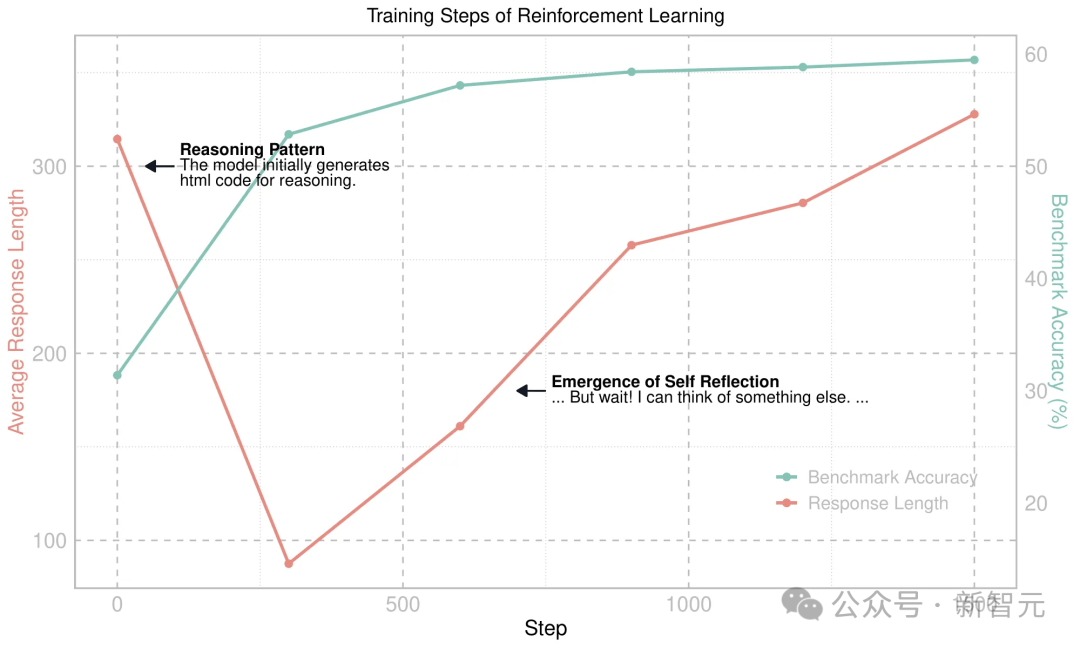
图1:VisualThinker-R1-Zero在Qwen2-VL基础模型上的训练动态变化
最初,研究者观察到了回答长度下降,因为基础模型倾向于生成HTML代码。通过强化学习,这种行为很快被抑制,随后回答长度开始规律地增加。之后,多模态的「啊哈时刻」出现了。随后,回答长度和基准准确率之间展现出一致的正相关关系。
具体来说,研究者从从Qwen2-VL-2B基础模型开始,直接在SAT数据集上进行强化学习。
没有任何SFT的情况下,模型就在CVBench上达到了59.47%的准确率,比基础模型高出约30%,比经过SFT的模型高出约2%。甚至,这个模型大幅超越了指令微调模型,而后者的训练数据明显更多。
现在,研究者已经在GitHub上开源了训练代码和关于回答长度的发研究发现,希望能加速AI社区未来对多模态推理的研究。
DeepSeek-R1的关键特征
DeepSeek-R1已经证明,强化学习可以在没有任何监督推理数据的情况下增强模型的推理能力。
这种成功背后,究竟包含着哪些关键特征?
研究者认真总结了这些特征,与自己的模型和其他多模态复现模型进行了比较。
在此过程中,他们格外强调两种显著的现象:「啊哈时刻」和响应长度的持续增长。
前者指的是模型在训练过程中,开始自主开发高级问题解决策略;后者则表明,模型在训练过程中自然学会了利用更长的思考时间来解决推理任务。
总之,如果复现模型并未展现出DeepSeek-R1的这些关键特征,那是否成功复现,就值得存疑。

DeepSeek-R1与多模态复现模型的比较
多模态的「 啊哈时刻」
在DeepSeek-R1-Zero训练过程中,观察到的一个特别引人入胜的现象,就是「 啊哈时刻」的出现:
. . .
等等,等等。等一下。我在这里发现了一个 啊哈时刻。
让我们重新一步步评估,以确定正确的计算结果是否可以 · · ·
. . .
这个「 啊哈时刻」表明,DeepSeek-R1-Zero能够自发构建推理策略,重新审视自己的初始方法,来提升自己的推理能力。
如下图所示,研究者在对以视觉为中心的推理任务进行强化学习训练期间,也观察到了类似行为——
模型展现出一种涌现能力,能够「重新审视」图像并纠正自身错误。
. . .
因此,带有白色毯子的深棕色木床不在门口上方。让我们重新一步步评估,但等等!我想到了其他可能。
也许它只是高于门口,但又略低于门框顶部。
. . .
这种多模态「 啊哈时刻」,加上响应长度的持续增长,证明了一个令人兴奋的事实:在视觉任务中,RL具有解锁全新层次智能的巨大潜力!

多模态大语言模型上的R1-Zero训练方法
所以,VisualThinker-R1-Zero究竟是怎样通过直接对未经SFT的基础模型应用RL训练,从而实现「啊哈时刻」的涌现的?
现有的将RL应用于微调视觉模型的项目,都未能复制DeepSeek-R1的关键特征。
而这项工作的研究者却独辟蹊径,发现了一种被忽视的方法——直接对未经监督微调的模型应用强化学习。
这种训练设置,就成了在多模态推理中实现真正「 啊哈时刻」的关键!
遵循DeepSeek-R1的做法,研究者们采取了一种简洁优雅的RL方法,避免使用奖励模型或类似于蒙特卡洛树搜索(MCTS)的技术。
具体来说,他们采用GRPO算法,并使用基于规则的奖励函数,根据响应的格式和正确性来评估:
团队的实现是基于DeepSeek-R1的报告,而初步实验表明,这种奖励函数有助于策略模型快速收敛,生成符合期望格式的响应。
实验
在实验中,研究团队微调了Qwen2-VL-2B基础模型,并在CV-Bench(一个以视觉为中心的基准测试套件)上评估其性能。
训练过程使用了来自SAT训练数据集的约12,000个查询,该数据集专注于空间推理问题。
与DeepSeek-R1-Zero类似,他们直接在基础模型上应用强化学习,而不进行任何监督微调。
这种方法比Qwen2-VL-2B(基础模型)提升了约30%的性能,比Qwen2-VL-2B-Instruct(指令微调模型)提升了约5%,比Qwen2-VL-2B SFT(基础+监督微调版)提升了约2%的基准性能。
这表明:视觉推理同样能从R1-Zero训练中获益。强化学习对多样化推理的探索,展现出了更具可扩展性的训练方法。
如下图2显示主要结果:R1方法相比基础模型和指令微调模型均取得了显著性能提升。
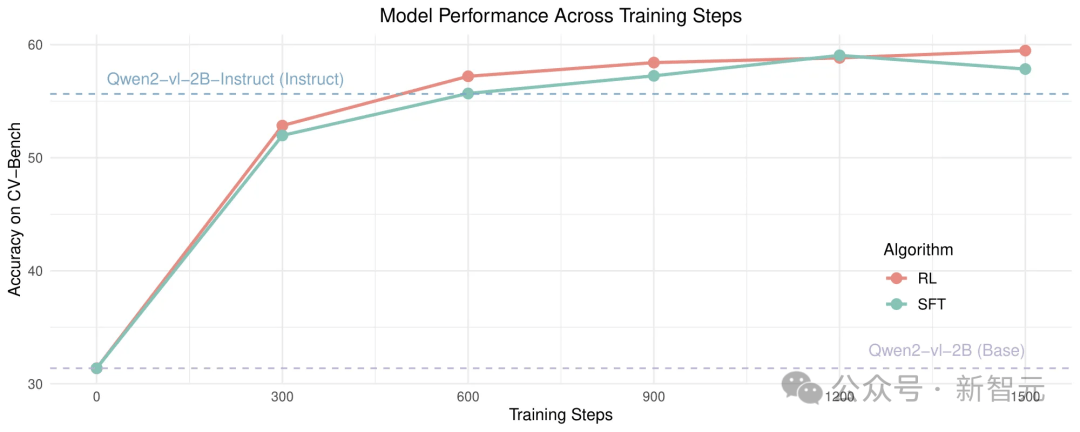
图2. 主要结果:该方法在基础模型和指令微调模型上取得了显著的改进
指令模型的早期实验与发现
很多研究者往往会倾向于直接对视觉指令模型应用强化学习,从而提升模型性能。
然而,研究团队在早期实验中却发现,尽管对指令模型应用GRPO确实提高了性能,但这种方法并未复现DeepSeek-R1报告中的观察结果和发现。
在此,他们也分享出了自己的失败案例。
不过,这也并不意味着这些方法就无法构建有效的视觉推理模型。
无实质内容的推理路径
与先前研究类似,他们最初对指令微调模型应用RL的尝试虽然提高了性能,但同时导致模型响应降级为无实质内容的表面推理与最终答案:
问题:
哪个物体距离拍摄这张照片的相机更近,盒子(红框标注)还是桌子(蓝框标注)?
模型:
<think>为了确定哪个物体距离相机更近,我将测量从相机到每个物体的距离。</think>
<answer>盒子</answer>
这就表明:模型可以通过GRPO提高性能,而不必真正发展出推理能力。
由此,就自然而然产生了这样一个问题:针对视觉中心任务的强化学习,是否主要改善了模型的视觉处理能力?
为了探究这一点,研究者们在RL过程中固定视觉编码器(不更新其参数)以评估其影响。(注意:以下结果不能直接与他们的主要结果进行比较,因为指令模型已经在数量明显更多的数据上进行了微调):
不同微调设置下模型在RL训练期间在CV-Bench上的准确率
下图3所示为强化学习训练过程中不同微调设置下响应长度的变化。横轴代表训练步骤,纵轴表示响应长度。图中比较了三种不同微调配置的模型:冻结大语言模型(绿色)、冻结视觉编码器(蓝色)和全参数微调(红色)。
可以看到,响应长度在训练初期显著下降,之后逐渐趋于稳定。
然而,尽管这三种基于RL的指令模型微调方法都提高了准确率,但却并未真正增强模型的推理能力,因为模型响应仍然很简单,且缺乏实质内容。

图3. 强化学习过程中不同微调设置下的回复长度随训练步骤变化的对比
有趣的是,在冻结视觉编码器的条件下,训练多模态大语言模型反而提高了性能,这一结果与研究者最初的假设相反。
然而,模型的响应依然简短且缺乏意义:

冻结大语言模型的强化学习实验
问题:
请估计图像中物体之间的实际距离。哪个物体与交通锥筒(红框标注)的距离更近,是摩托车(蓝框标注)还是公交车(绿框标注)?
模型:
<think>为了确定哪个物体与交通锥筒距离更近,让我们分析图像中物体之间的距离。</think>
<answer>摩托车</answer>

冻结视觉编码器的强化学习实验
问题:
请估计图像中物体之间的实际距离。哪个物体与交通锥筒(红框标注)的距离更近,是摩托车(蓝框标注)还是公交车(绿框标注)?
模型:
<think>为了确定哪个物体与交通锥筒(红框标注)距离更近,我们需要分析图像中物体之间的距离。</think>
<answer>摩托车</answer>
这一现象表明,还需要进行更深入的研究,来理解这种性能改进的原因。
单纯奖励更长回答,能否提高模型性能?
研究团队还探究了另一个问题:回答长度本身,是否是提升推理能力的关键因素?
为此,他们设计了一项实验,评估简单激励模型生成更长回答是否能提升其推理能力。为此,他们对模型生成的每个额外token给予+0.001的奖励。
然而,实验结果表明,单纯奖励回答长度并不能提高模型性能:
下图4显示了在指令微调模型上应用长度奖励的强化学习训练过程中的模型性能变化。
可以看到,虽然平均回答长度(红线)显著增长,但基准测试准确率(绿线)保持相对稳定,这表明更长的回答并不必然带来更强的推理能力。
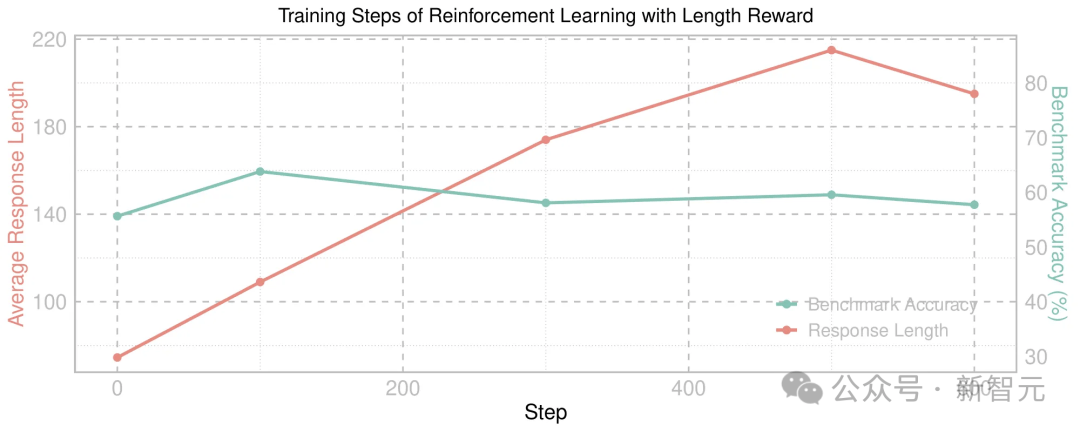
图4. 在经指令微调的模型上应用基于长度奖励的强化学习训练过程中的性能表现
很快,模型就学会了钻长度奖励的空子,生成极长但毫无意义的错误回答:

问题:
考虑图像中长颈鹿(红框标注)和人物的相对位置,长颈鹿相对于人物处于什么位置?
模型:
<think>
- 长颈鹿(红框标注)位于图像前景。
- 人物在背景中,站在长颈鹿后方。
- 长颈鹿比人物更靠近观察者。
- 人物不在长颈鹿正上方。
- 人物不在长颈鹿正下方。
- 长颈鹿不在人物上方。
- 长颈鹿不在人物下方。
- 人物不在长颈鹿前面。
- 人物不在长颈鹿后面。
- 人物不在长颈鹿左侧。
- 人物不在长颈鹿右侧。
- [重复内容直到达到最大token数限制]
这一结果表明,简单基于长度的奖励机制并不能有效提高模型性能。
研究者建议,未来的研究可以探索设计更优的长度奖励机制,以鼓励模型生成有意义的推理步骤。
在后续研究中,他们将探索响应长度与多模态推理之间的关系,泛化能力与记忆能力的对比,以及R1方法何时有效及其工作原理。
未来计划
进一步分析多模态推理中响应长度的作用
利用经人工筛选的R1-Zero推理路径进行监督微调来复现R1方法
作者介绍
Hengguang Zhou

Hengguang Zhou是加州大学洛杉矶分校(UCLA)一年级的研究生,同时也是TurningPoint AI项目的负责人,该项目由Ruochen Wang和Cho-Jui Hsieh教授指导。
他的研究主要聚焦于多模态大型语言模型的安全性。在LLM时代之前,有从事3D计算机视觉、人机交互(HCI)和视觉丰富的文档理解方面工作的经验。
他在多伦多大学计算机科学获得学士学位。
Xirui Li

Xirui Li是加州大学洛杉矶分校(UCLA)的博士研究生。研究重点是可信AI,特别是基础模型(LLMs/VLMs)的可控性和解释性。
在大语言模型兴起之前,他的研究方向是目标检测和视觉解释技术。除学术研究外,也对创业机会有浓厚兴趣。
目前,他是TurningPoint AI的成员,这是一个由多个实验室联合组建的AIGC研究合作组织,专注于多模态AI智能体的研究,由Dr. Ruochen Wang和Cho-Jui Hsieh教授指导。
他在慕尼黑工业大学获得电气与计算机工程学士学位。期间,在Hao Shen和Tianming Qiu博士的指导下完成了关于Transformer目标检测可解释性的论文。
Ruochen Wang

Ruochen Wang在OpenAI从事多模态研究工作。目前对风险投资和创业有浓厚的兴趣。
他在密歇根大学获得计算机科学和统计学学士学位,并以最高荣誉毕业。在加州大学洛杉矶分校获得计算机科学硕士学位。在加州大学洛杉矶分校获得计算机科学博士学位,期间创立并领导了TurningPoint AI研究团队。
此外,他还与谷歌研究/DeepMind有合作关系。并以第一作者身份,获得了ICLR优秀论文奖。
Minhao Cheng

Minhao Cheng是宾夕法尼亚州立大学信息科学与技术学院助理教授。目前研究兴趣主要在机器学习领域,重点关注可信机器学习和AutoML。
此前,他曾在香港科技大学担任计算机科学与工程助理教授。
他在电子科技大学获得计算机科学与技术学士学位,在加州大学洛杉矶分校计算机科学系获得博士学位,导师是Cho-Jui Hsieh教授。
Tianyi Zhou

Tianyi Zhou是马里兰大学帕克分校计算机科学、UMIACS和AIM的终身制助理教授。目前研究兴趣在机器学习、优化和自然语言处理。
2021-2022年间,他在担任谷歌的访问研究科学家,由Boqing Gong和Ming-Hsuan Yang教授指导。
他在华盛顿大学获得计算机科学博士学位,是Jeff A. Bilmes教授领导的MELODI实验室成员。并曾在悉尼科技大学(UTS)和南洋理工大学担任研究助理,与Dacheng Tao(陶大程)教授合作。
此外,他还曾在雅虎实验室担任研究实习生,由Hua Ouyang博士(苹果)和Yi Chang教授(吉林大学)指导,并曾在微软研究院实习,由Lin Xiao博士(Meta AI)指导。
Cho-Jui Hsieh

Cho-Jui Hsieh是加州大学洛杉矶分校(UCLA)计算机科学系副教授。
他的研究兴趣是开发用于大规模机器学习问题的新算法和优化技术。目前,正在致力于开发新的机器学习模型,以及改进(深度学习)模型的大小、训练速度、预测速度和鲁棒性。
此前,他曾在加州大学戴维斯分校(UC Davis)计算机科学和统计学系担任助理教授三年,并自2018年夏起在谷歌公司担任访问学者。
他在德克萨斯大学奥斯汀分校获得博士学位,导师是Inderjit Dhillon教授。在台湾大学获得硕士学位,导师是Chih-Jen Lin教授。

