1956年夏天,新罕布什尔州达特茅斯学院迎来了一场特殊的学术聚会。当数学教授约翰·麦卡锡在会议提案中首次写下“Artificial Intelligence”这个术语时,或许未曾料到,这场原本计划用两个月时间“彻底解决机器模拟智能问题”的讨论,竟开启了一场跨越世纪的认知革命。
阿里巴巴集团CEO吴泳铭在财报会议上语气铿锵,仿佛预见到历史转折的关键瞬间:“一旦AGI真正实现,其所催生的产业规模,极有可能问鼎全球之首,甚至有可能深刻地影响、乃至部分取代当下全球经济构成中近半壁江山的产业形态。”
在惊喜与担忧之间,人们正学着接纳和拥抱人工智能,惴惴不安地揣测着通用人工智能(AGI)何时到来。然而,作为掀起本轮AI热潮的主角,大语言模型或许还只是一个探路者,离真正的AGI仍相距甚远,甚至根本不是通达AGI的正途。对此,人们不免心生疑问,我们离实现真正的AGI还有多远?
谁是AGI的起点?
“通用人工智能(Artificial General Intelligence)”一词最初出现在北卡罗莱纳大学物理学家Mark Gubrud于1997年发表的一篇有关军事技术的文章中,其中将AGI定义为“在复杂性和速度上与人脑相媲美或超越的AI系统,可以获取一般性知识,并以其为基础进行操作和推理,可以在任何工业或军事活动中发挥人类智力的作用。”
一直以来,AGI被视为人工智能领域的“圣杯”,它意味着机器能够像人类一样,在多种任务中自主学习、推理并适应复杂环境。从GPT-4的对话能力到Sora的视频生成,尽管近年来AI技术突飞猛进,但AGI的实现仍面临多重鸿沟。
AI的核心就是把现实世界的现象翻译成为数学模型,通过语言让机器充分理解现实世界和数据的关系。而AGI更进一步,让AI不再局限于单一任务,而是具备跨领域学习和迁移能力,因此具有更强的通用性。
如果比较AGI的特征,就会发现当前AI系统虽然在特定任务上超越人类(如文本生成、图像识别),但本质上仍是“高级模仿”,缺乏对物理世界的感知和自主决策能力,依然不符合AGI的要求。
首先,大模型在处理任务方面的能力有限,它们只能处理文本领域的任务,无法与物理和社会环境进行互动。这意味着像ChatGPT、DeepSeek这样的模型不能真正“理解”语言的含义,因为它们没有身体来体验物理空间。
其次,大模型也不是自主的,它们需要人类来具体定义好每一个任务,就像一只“鹦鹉”,只能模仿被训练过的话语。真正自主的智能应该类似于“乌鸦智能”,能够自主完成比现如今AI更加智能的任务,当下的AI系统还不具备这种潜能。
第三,虽然ChatGPT已经在不同的文本数据语料库上进行了大规模训练,包括隐含人类价值观的文本,但它并不具备理解人类价值或与人类价值保持一致的能力,即缺乏所谓的道德指南针。
但这些并不妨碍科技巨头对于大模型的推崇。OpenAI、谷歌在内的科技巨头,都将大模型视为迈向AGI的关键一步。OpenAI CEO萨姆·奥特曼(Sam Altman)就曾多次表示,GPT模型是朝着AGI方向发展的重要突破。
根据OpenAI提出的AGI五级标准:L1是聊天机器人(Chatbots),具备基本的会话语言能力;L2是推理者(Reasoners),能够解决人类级别的问题,处理更复杂的逻辑推理、问题解决和决策制定任务;L3是智能主体(Agents),能够代表用户采取行动,具备更高的自主性和决策能力;L4是创新者(Innovators),能够助力发明和创新,推动科技进步和社会发展;L5是组织者(Organizations),能够执行复杂的组织任务,具备全面管理和协调多个系统和资源的能力。
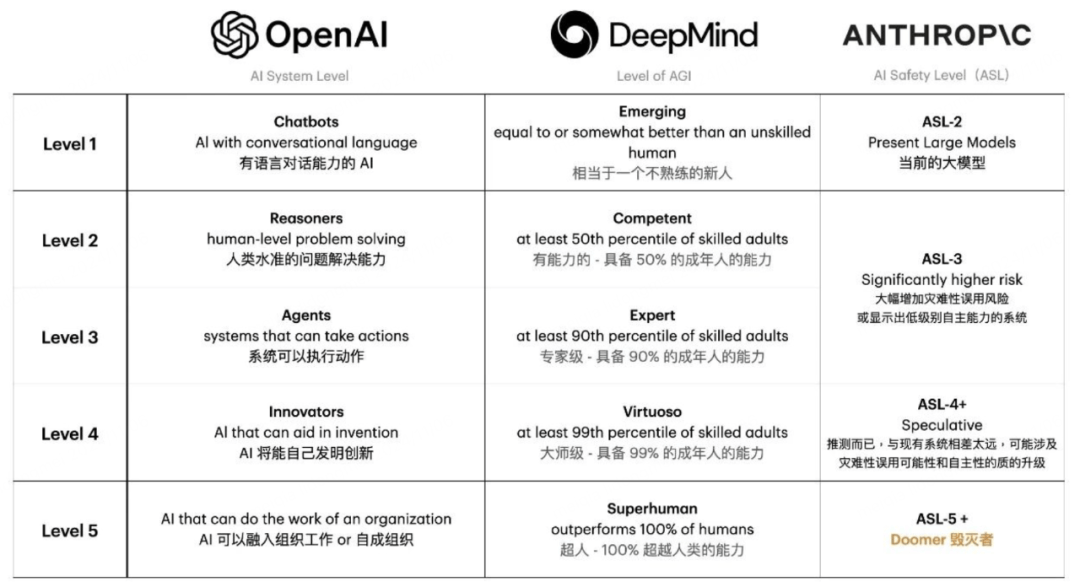
当前,AI技术正从L2“推理者”向L3“智能体”阶段跃迁,而2025年成为Agent(智能体)应用爆发之年是业内共识,我们已经看到像ChatGPT、DeepSeek、Sora这类应用开始进入普及阶段,融入人们的工作生活。
但通往AGI的道路仍布满认知陷阱,大模型偶尔出现的“幻觉输出”,暴露出当前系统对因果关系的理解局限;自动驾驶汽车面对极端场景的决策困境,折射出现实世界的复杂性与伦理悖论。
就像人类智能进化塑造的是多层架构,既有本能层面的快速反应,也有皮层控制的深度思考。要让机器真正理解苹果落地背后的万有引力,不仅需要数据关联,更需要建立物理世界的心智模型。这种根本性的认知鸿沟,可能比我们想象中更难跨越。
通向AGI的必经之路
大模型的演进将会经历三个阶段:单模态→多模态→世界模型。
早期阶段是语言、视觉、声音各个模态独立发展,当前阶段是多模融合阶段,比如GPT-4V可以理解输入的文字与图像,Sora可以根据输入的文字、图像与视频生成视频。
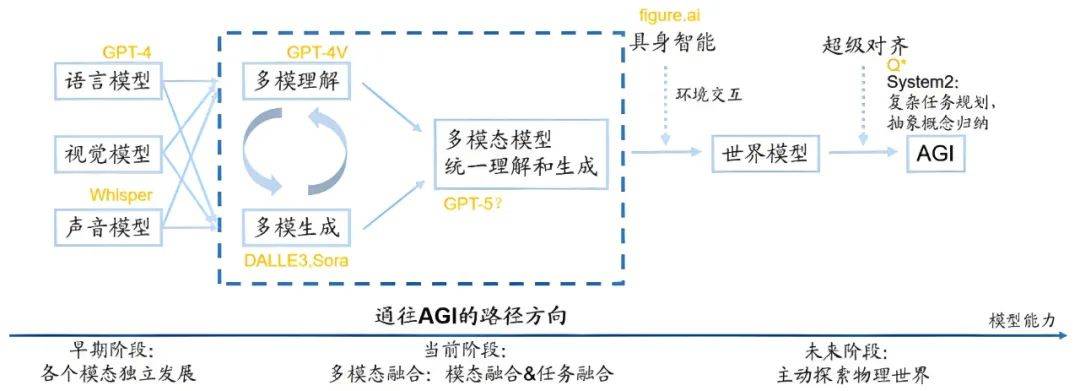
但现阶段的多模态融合还不彻底,“理解”与“生成”两个任务是分开进行的,造成的结果是GPT-4V理解能力强但生成能力弱,Sora生成能力强但理解能力有时候很差。多模态理解与生成的统一是走向AGI的必经之路,这是一个非常关键的认知。
无论通过哪种路径实现AGI,多模态模型都是不可或缺的一部分。人与现实世界的交互涉及多种模态信息,因此,AI必须处理和理解多种形式的数据,这意味着其必须具备多模态理解能力。
多模态模型能够处理和理解不同模态数据的机器学习模型,如图像、文本、音频和视频,能够提供比单一模态更全面、更丰富的信息表达。此外,模拟动态环境变化并做出预测和决策,也需要强大的多模态生成能力。
不同模态的数据往往包含互补的信息,多模态学习能够有效地融合这些互补信息,提高模型的准确性和鲁棒性。例如,在图像标注任务中,文本信息可以帮助模型更好地理解图像内容;而在语音识别中,视频信息有助于模型捕捉说话者的唇动,从而提高识别准确率。
通过学习和融合多种模态的数据,模型能够建立更加泛化的特征表示,从而在面对未见过的、复杂的数据时表现出更好的适应性和泛化能力。这对于开发通用智能系统和提高模型在现实世界应用中的可靠性具有重要意义。
多模态模型的研究大致可以分为几种技术途径:对齐、融合、自监督和噪声添加。基于对齐的方法将不同模态的数据映射到一个共同的特征空间进行统一处理。融合方法将多模态数据整合到不同的模型层中,充分利用每个模态的信息。自监督技术在未标记的数据上对模型进行预训练,从而提高各种任务的性能。噪声添加通过在数据中引入噪声来增强模型的鲁棒性和泛化能力。
结合这些技术,多模态模型在处理复杂的现实世界数据方面表现出强大的能力。它们可以理解和生成多模态数据,模拟和预测环境变化,并帮助智体做出更精确和有效的决策。因此,多模态模型在发展世界模型中起着至关重要的作用,标志着迈向AGI的关键一步。
比如微软近日开源了多模态模型Magma,不仅具备跨数字、物理世界的多模态能力,能自动处理图像、视频、文本等不同类型数据,还能够推测视频中人物或物体的意图和未来行为。
阶跃星辰两款Step系列多模态大模型Step-Video-T2V、Step-Audio已与吉利汽车星睿AI大模型完成了深度融合,推动AI技术在智能座舱、高阶智驾等领域的普及应用。
蘑菇车联深度整合物理世界实时数据的AI大模型MogoMind,具备多模态理解、时空推理与自适应进化三项能力,不仅能够处理文本、图像等数字世界数据,还能通过城市基础设施(如摄像头、传感器)、车路云系统以及智能体(如自动驾驶车辆)实现对物理世界的实时感知、认知和决策反馈,突破了传统模型依赖互联网静态数据训练、无法反映物理世界实时状态的局限。同时,该大模型还重构视频分析范式,使普通摄像头具备行为预测、事件溯源等高级认知能力,为城市和交通管理者提供流量分析、事故预警、信号优化等服务。
不过,多模态在发展过程中,还需要面临数据获取和处理的挑战、模型设计和训练的复杂性,以及模态不一致和不平衡的问题。
多模态学习需要收集和处理来自不同源的数据,不同模态的数据可能有着不同的分辨率、格式和质量,需要复杂的预处理步骤来确保数据的一致性和可用性。此外,获取高质量、标注精确的多模态数据往往成本高昂。
其次,设计能够有效处理和融合多种模态数据的深度学习模型比单模态模型更加复杂。需要考虑如何设计合适的融合机制、如何平衡不同模态的信息贡献、以及如何避免模态间的信息冲突等问题。同时,多模态模型的训练过程也更为复杂和计算密集,需要更多的计算资源和调优工作。
在多模态学习中,不同模态之间还可能存在显著的不一致性和不平衡性,如某些模态的数据可能更丰富或更可靠,而其他模态的数据则可能稀疏或含噪声。处理这种不一致和不平衡,确保模型能够公平、有效地利用各模态的信息,也是多模态学习中的一个重要挑战。
当前,大语言模型、多模态大模型对人类思维过程的模拟还存在天然的局限性。从训练之初就打通多模态数据,实现端到端输入和输出的原生多模态技术路线给出了多模态发展的新可能。基于此,训练阶段即对齐视觉、音频、3D等模态的数据实现多模态统一,构建原生多模态大模型,成为多模态大模型进化的重要方向。
将AI拉回现实世界
Meta人工智能首席科学家杨立昆(Yann LeCun)认为,目前的大模型路线无法通往AGI。现有的大模型尽管在自然语言处理、对话交互、文本创作等领域表现出色,但其仍只是一种“统计建模”技术,通过学习数据中的统计规律来完成相关任务,本质上并非具备真正的“理解”和“推理”能力。
他认为,“世界模型”更接近真正的智能,而非只学习数据的统计特征。以人类的学习过程为例,孩童在成长过程中,更多是通过观察、交互和实践来认知这个世界,而非被单纯“注入”知识。
例如,第一次开车的人在过弯道的时候会自然地“知道”提前减速;儿童只需要学会一小部分(母语)语言,就掌握了几乎这门语言的全部;动物不会物理学,但会下意识地躲避高处滚落的石块。
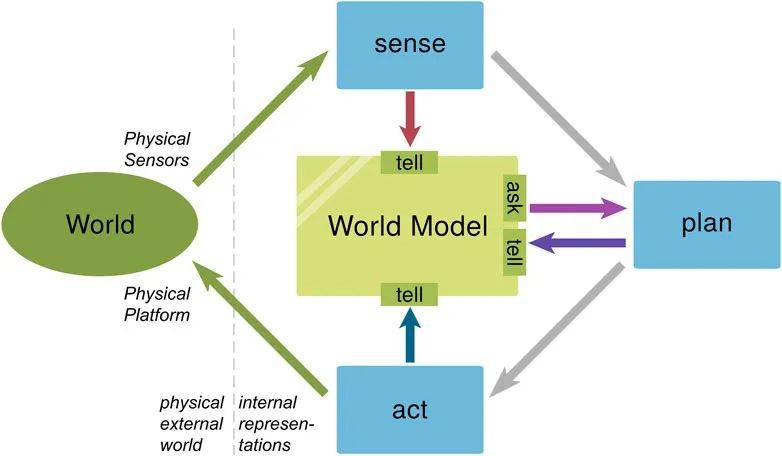
世界模型之所以引起广泛关注,原因在于其直接面对了一个根本性的难题:如何让AI真正理解和认识世界。它正试图通过对视频、音频等媒体的模拟与补全,让AI也经历这样一个自主学习的过程,从而形成“常识”,并最终实现AGI。
世界模型和多模态大模型主要有两方面不同之处,一是世界模型主要通过包括摄像头在内的传感器直接感知外部环境信息,相比于多模态大模型,其输入的数据形式以实时感知的外部环境为主,而多模态大模型则是以图片、文字、视频、音频等信息交互为主。
另一方面,世界模型输出的结果,更多的是时间序列数据(TSD),并通过这个数据可以直接控制机器人。同时物理智能需要与现实世界进行实时、高频交互,其对时效性要求较高,而多模态大模型更多是与人交互,输出的是过往一段时间的静态沉淀信息,对时效性要求较低。
也正因此,世界模型也被行业人士看作是实现AGI的一道曙光。
世界模型的发展虽然取得了显著进展,但仍面临多方面的挑战。挑战之一是在模拟环境动态及因果关系方面的能力,以及进行反事实推理的能力。反事实推理要求模型能够模拟如果环境中的某些因素发生变化,结果会如何不同,这对于决策支持和复杂系统模拟至关重要。
例如,在自动驾驶中,模型需要能够预测如果某个交通参与者的行为发生变化,车辆的行驶路径会受到怎样的影响。然而,当前的世界模型在这一领域的能力有限,未来需要探索如何让世界模型不仅反映现实状态,还能根据假设的变化做出合理的推断。
物理规则的模拟能力是世界模型面临的另一大挑战,尤其是如何让模型更加精确地模拟现实世界中的物理规律。尽管现有的视频生成模型如Sora可以模拟一定程度的物理现象(如物体运动、光反射等),但在一些复杂的物理现象(如流体动力学、空气动力学等)中,模型的准确性和一致性仍然不足。
为了克服这一挑战,研究人员需要在模拟物理规律时,考虑更精确的物理引擎与计算模型,确保生成的场景能够更好地遵循真实世界中的物理定律。
评估世界模型性能的关键标准之一是泛化能力,其强调的不仅是数据内插,更重要的是数据外推。例如,真实的交通事故或异常的驾驶行为是罕见事件。那么,学习得到的世界模型能否想象这些罕见的驾驶事件,这要求模型不仅要超越简单地记忆训练数据,而且要发展出对驾驶原理的深刻理解。通过从已知数据进行外推,并模拟各种潜在情况,使其可以更好地应用于现实世界之中。
对于AI而言,让机器人亲自拧开瓶盖获取的数据,比观看百万次操作视频更能建立物理直觉。通过在模型训练过程中加入更多真实场景的实时动态数据,可以让AI更好理解三维世界的空间关系、运动行为、物理规律,从而实现对物理世界的洞察和理解。最终,AGI的到来可能不像奇点理论预言的那般石破天惊,而会像晨雾中的群山,在数据洪流的冲刷下渐次显形。
AI的尽头并非一个固定终点,而是人类与技术共同书写的未来叙事。它可能是工具、伙伴、威胁,或是超越想象的形态。关键问题或许不是“AI的尽头是什么”,而是“人类希望以何种价值观引导AI的发展”。正如斯蒂芬·霍金所警示:“AI的崛起可能是人类最好或最糟的事件。”答案取决于我们今天的决策与责任,届时AI将重新认识世界,并完成对未来人机交互方式的重新想象。

