最近有很多小伙伴在问我们关于DeepSeek的原理、怎么部署、怎么用好各种五花八门的问题,于是至顶AI实验室整理了一份实用手册来一一解答。
手册从发展脉络,到个人和企业使用部署方案,再到“DeepSeek+”使用技巧,对DeepSeek进行全方位解读,适合想用和用好DeepSeek的企业和个人阅读。


▋ DeepSeek是谁?

DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,简称深度求索,成立于2023年7月,是幻方量化旗下的AI公司,专注于实现通用人工智能(AGI),具有深厚的软硬件协同设计底蕴。自成立以来,DeepSeek致力于研发和开源一系列高性能的AI模型,旨在推动AI技术的普及和应用,为全球的科研人员和技术开发者提供强大的工具和平台。
▋ DeepSeek的技术路线解析
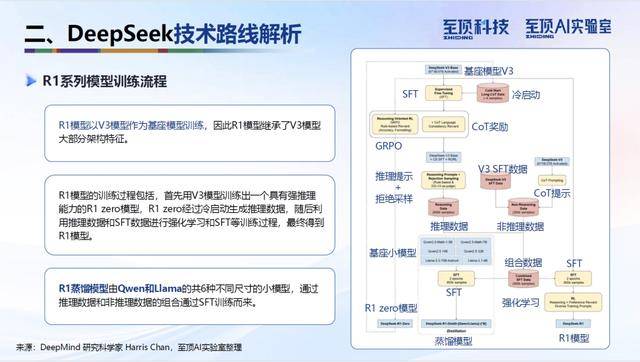
DeepSeek的技术路线以其创新性和实用性著称。其核心技术包括混合专家架构(MoE)、多头潜在注意力(MLA)、多词元预测训练(MTP)以及FP8混合精度训练等。这些技术不仅提升了模型的性能,还显著降低了训练和推理成本,使得DeepSeek的模型在性价比上具有显著优势。
(一)混合专家架构(MoE)
MoE架构是DeepSeek模型的核心之一,它通过路由和专家两部分的协同工作,实现了数据的高效处理。每个MoE层包含1个共享专家和256个路由专家,在运行时每个词元(token)只激活8个路由专家。这种设计不仅节约了计算资源,还使得模型在处理复杂任务时更具优势。
(二)多头潜在注意力(MLA)
MLA通过对注意力键和值进行低秩联合压缩,减少了推理过程中的键值缓存(KV cache),从而降低了推理时的内存占用。引入旋转位置编码(RoPE)保持位置信息的有效表示,使得模型在处理长上下文时更加得心应手。
(三)多词元预测训练(MTP)
MTP技术通过在训练过程中让模型不仅预测下一个词元,还预测多个未来的词元,从而提高了模型的预测能力和效率。这种设计通过在共享模型主干上增加多个独立的输出头来实现,不增加训练时间和内存消耗。
(四)FP8混合精度训练
FP8混合精度训练技术通过使用细粒度量化策略、低精度优化器状态等方法,实现了增强精度、低精度存储和通信。这一技术不仅降低了存储占用,还提高了训练效率,为DeepSeek模型的高效训练提供了有力支持。
▋ DeepSeek为什么火?
DeepSeek之所以能够在短时间内引起广泛关注,主要得益于其在性能、成本和开源程度等方面的突出表现。
(一)性能比肩国际顶尖模型

DeepSeek-R1模型在AI模型基准能力的各大榜单中,得分与OpenAI的o1模型不相上下,终结了中国AI模型落后于美国模型半年到一年的局面。作为国产模型,DeepSeek对中文支持更好,能够更好地满足国内用户的需求。
(二)低训练成本和推理成本
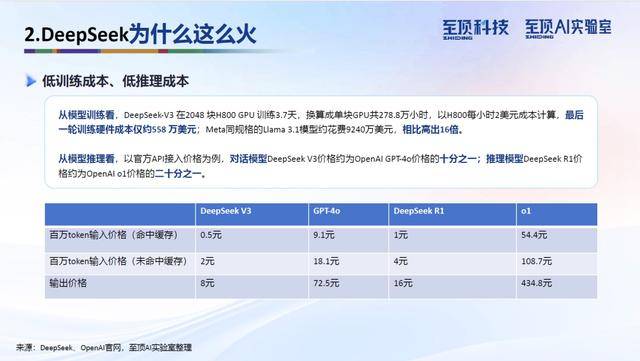
DeepSeek-V3模型的训练成本仅为约558万美元,相比Meta同规格的Llama 3.1模型约9240万美元的训练成本,低了16倍。在推理成本方面,DeepSeek V3和R1模型的价格分别为OpenAI GPT-4o和o1模型的十分之一和二十分之一,显著降低了用户的使用成本。
(三)高度开源
DeepSeek系列模型完全开源,符合开放源代码促进会(OSI)发布的开源AI定义1.0(OSAID 1.0)的所有要求。开源策略不仅吸引了大量开发者关注和使用,还促进了技术的快速传播和创新,为AI技术的发展注入了新的活力。
▋ DeepSeek的调用与部署
DeepSeek模型的调用与部署方式灵活多样,用户可以根据自身需求选择云端调用或本地部署,也可以直接购买各大品牌的DeepSeek一体机。
(一)云端调用
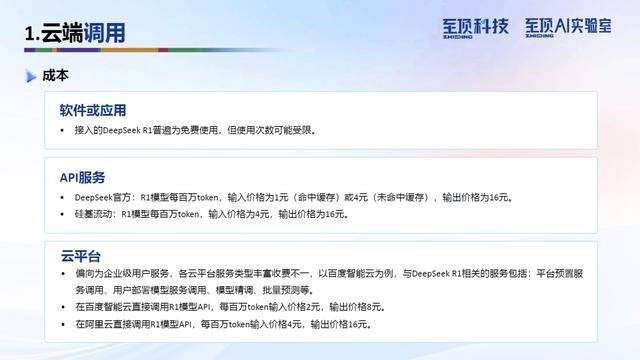
云端调用通过官方API或第三方API直接调用DeepSeek R1模型服务并接入业务中,用户无需购置硬件即可按需调用云端模型。这种方式适合对硬件要求不高、数据安全要求较低的场景。
(二)本地部署

本地部署需要用户下载DeepSeek R1满血版或蒸馏版本模型,通过Ollama、vLLM等工具启动模型,并借助可视化界面工具与用户交互。本地部署适合对数据安全要求高的企业私有化场景,但需要满足高性能显卡和服务器的硬件配置要求。
▋ 如何使用DeepSeek?
DeepSeek的使用可以分为独立使用和工具组合使用两种方式。
(一)独立使用
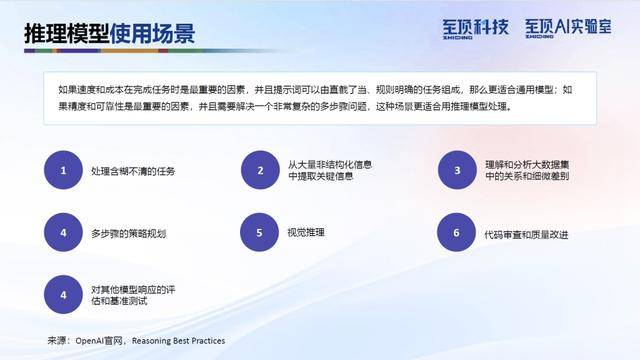
通过自然语言对话获取核心服务,典型场景包括文本创作、信息咨询、知识推理等。用户只需输入需求指令,即可直接获取生成内容,操作简单便捷。这部分我们还分享了OpenAI的推理提示词模版和适用的场景类别。
(二)工具组合使用

基于文本指令驱动的工具生态协同,实现“DeepSeek+”创新工作流。典型组合形态包括创意设计、办公增效、多媒体生产、编程辅助等。通过与XMind、飞书、Kimi、Mermaid、讯飞听见、Obsidian、Excel、LobeChat、Photoshop、MidJourny、即梦、Tripo、Suno、Heygen、剪映、HBuilder、Cline等工具的结合,DeepSeek能够帮助用户在复杂的工作环境中保持高效、井然有序的工作流程。
▋ 结语:趋势判断
DeepSeek的出现,不仅标志着中国AI技术在国际舞台上的崛起,也为AI应用生态的加速繁荣注入了新的动力。开源模型的普及,将进一步降低企业与创业者接入AI的成本与门槛,推动AI技术的广泛应用。同时,AI技术的深入演进,使得推理模型有望成为主流形态,为复杂任务的解决提供更精准、更可靠的方案。未来,每项业务、每位工作者、每个公司都将与AI技术紧密相连,共同推动智能变革的新潮流。

