人工智能逐渐成年、大模型纷飞、军备竞赛加剧、国产大模型腾飞,特别是推理大模型盛行,在这样的国内外大势下,作为科研工作者、研发型药企,我们该如何甄别和拥抱人工智能?
作为AI+药物的资深参与者,AI+药物递送和AI+纳米材料的开启者,剂泰医药将围绕以下两个核心话题展开讨论:
1、什么是大模型和推理大模型?
2、药企使用大模型的几种模式。
在第一期,我们将先为大家科普大模型和推理大模型。下一期,我们将结合当前的形势分析大模型和大模型算法在药企落地的思路。
什么是大模型?
简单来说就是基于大数据进行训练,具有非常大参数量和复杂结构的深度学习模型。
大数据指的通常是能收集到的大量自然语言语料,既包含了日常对话,又包含了人类文明和智慧的结晶,可以类比为人的大脑接收到的大量听觉、视觉信息。
大参数量指的是由于需要训练大量数据,就需要深度学习具有很大的网络来融会贯通这些数据,可以类比为大脑的神经元。
这两者的完成需要另一个铁三角,算力,大量的数据存储和计算需要载体或者计算资源,通常是GPU,可以类比为大脑处理信息所需要的能量和脑容量。
大模型的崛起和Transformer架构分不开,Transformer的本质是可以利用注意力机制,找到每个Token(可以理解为词语)之间的相互关系,使机器学会语言的前后联系,融会贯通。大模型的学习类似于人的学习,通过完形填空(masking)和组词(next token prediction)等方式帮助大家理解(encoder,BERT)和生成语言(decoder,GPT)。
大模型的预训练类似于题海战术学习备考,推理类似于最后的考试,题海覆盖越广、理解越深,最后的考试就答得越快越好。或者说,预训练可以类比于在学校的学习,而另一个概念微调就类似于毕业后的就业,同一个知识体系可以做科学家也可以做管理者,只是后期的细分不一样。
剂泰医药AiLNP平台的脂质语言模型(LipidBERT)和脂质生成模型(PhatGPT)就分别是对特殊而专业的脂质语言做的理解和生成。
剂泰医药从成立以来就一直专注的干湿迭代也在预训练和微调上找到了最佳实践,用剂泰专有的脂质和LNP干实验数据预训练,用剂泰专有的高通量湿实验数据库做微调,打造了世界上第一个基于预训练+微调的脂质语言和生成模型,让人工智能学习脂质的语言,可以根据“看”过的脂质结构和实验数据,“理解”脂质和LNP的内在语境,“说”出全新的脂质话语和性质。
剂泰的AiRNA平台同样融合了对蛋白和RNA等生物语言的理解和生成,干湿迭代,和AiLNP交相呼应,一个设计核酸内核、一个设计LNP外壳,内外兼修,将核酸分子精准递送到各个器官和细胞。
图1:基于强化学习、Transformer、GPT、Diffusion,融合了干湿迭代的剂泰医药千万级别脂质库缩影
什么是推理大模型?
scaling law认为模型的效果和训练数据、参数量以及算力直接相关,三个方面越大,效果越好,欧美的大模型追求大大大,促生了大模型的军备竞赛。
但科学家们发现,大到一定程度后,成本居高不下,效果未必提高得那么快。大家发现,一昧地只疯狂训练,大未必佳,推理是被忽略的一个点。
早期大模型和推理大模型的区别,本质上就是人们从关注train-time scaling law转向也同时关注test-time scaling law。其实以著名的Chain of thought(思维链)为首的Prompting(提示词)到In-context learning(语境学习),大家也在关注回答问题的思维模式,激发模型的推理能力。但这些方法都并没有对模型本身的知识体系产生影响,没法让模型自主地做更深层次的推理。
从OpenAI的o1模型开始,大家开始真正关注从模型内部改变推理的模式,教模型怎么推理,让模型自主推理,改变模型的思维模式。而DeepSeek-R1将推理大模型打上了中国的标签,标志了中国大模型的腾飞,它将推理数据、强化学习和SFT(有监督微调)穿插使用,融会贯通,使大模型在做高难度数学题和复杂问题推理上的能力达到世界最先进水平,并完全开源,真正做到强大又透明。
这里提到的推理大模型虽然也是基于思维链(CoT),但和早期的CoT存在本质区别。早期的CoT是通过改变模型外部或后期的思维模型间接地、暂时地改变模型的推理,推理大模型则是通过显式的CoT数据通过强化学习或有监督微调本质上改变模型的推理模式,从内而外直接地、永久地教模型推理。
用一个例子解释,前文提到大模型用预测下一个字符的方式,依次根据前面累积的字符输出下一个字符的概率分布,从而确定下一个字符。假设模型得到的问题是:“张三有3个苹果,4个香蕉,其中1个香蕉是烂的,请问张三有几个不烂的苹果?”
正常按照预测下一个字符的思想,模型会根据以上的序列直接输入下一个字符,有可能会出现8、4或2等错误答案,其实不包含太多计算,只是通过学习了各种语言,输出概率最大的下一个字符,简单的问题没有问题,但遇到复杂的计算就会出错。
而推理大模型下,机器可能输出的下一个字符可能是“第”或“让”,这两个字符可能就会逐步触发下面的“第一,我们先”、“让我们分步思考”、“让我们列个方程”、“让我首先理解一下这个问题”等,然后通过模型学到的推理步骤逐步展开,在各步骤里通过不同的搜索和采样方式,根据从强化学习等方法学到的方法,选取合适的推理过程,最终给出答案,这样的一步步推理在比以上问题难很多的复杂问题上非常有用。
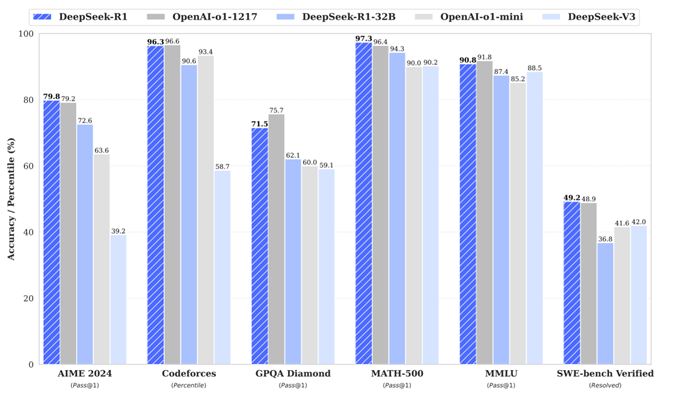
图2:DeepSeek和OpenAI模型效果对比(来自DeepSeek的文章)
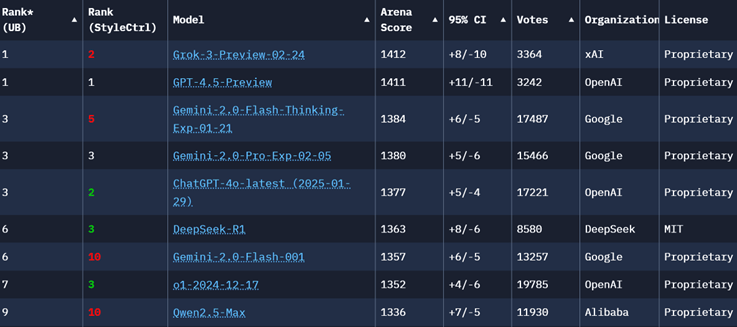
图3:大模型排名榜(来自权威的大模型竞技场)
DeepSeek-R1自从发布以来,不停刷榜,也刷新了人类对于中国大模型的认知。DeepSeek发扬了中国的务实精神,不盲目追求模型大,而是以更聪明的方式去优化算法、工程和硬件模式和高质量数据,打了一场漂亮的游击战和反击战。
DeepSeek将传统Transformer架构中的attention模块进行了优化,也优化了KV缓存,使效率更高,并将FFN(前馈神经网络)换成了MoE(混合专家模型)。MoE里的专家可以类比为多位不同科室的专家,根据来的病人(语料)的不同,通过一个类似于分诊台的gating(门控)的模式选择合适的一位或几位医生,通过会诊的形式进行治疗,其中还增加了一位Shared expert,让这位医生参与每次诊断,可以具备交叉知识。相比于要求一个医生精通所有类别,这样的方式操作难度小。
DeepSeek-R1-Zero完全通过强化学习,而不通过有监督微调,用一个简单的指令教模型推理,并对格式做出要求,甚至不包含显式地要求模型分步思考、自我反省等指令,用格式奖励和回答正确两种奖励就让模型具备了一定的推理技巧。
值得一提的是,最新出炉的2024年ACM图灵奖授予了两位强化学习的先驱Andrew Barto和Richard Sutton,图灵奖号称“计算机领域的诺贝尔奖”,强化学习的获奖也代表了计算机界对强化学习广泛应用的认可。
在发现Zero模型出现缺陷之后,DeepSeek团队针对Zero模型答案的可读性不强和语言混乱等问题做了优化,用了两次强化学习和两次有监督微调,加入了语言奖励和偏好奖励,并用自己高质量推理思维链数据集、通用数据集以及模型自己产生的合成数据对模型进行训练,最终达到了世界顶级水平。
剂泰的AiLNP和AiRNA平台都用到了强化学习,反复迭代模型,用AI提高实验效率,更快找到最优解。其中AiLNP更是在领域无脂质结构数据的基础上,根据内部药化和计算化学专家的理解设计奖励函数,只通过强化学习产生高质量的合成数据,结合实验反复迭代,最终形成了世界上第一个、最大、最多样性的脂质库。基于脂质库又通过预训练和有监督微调等方法开发了多个语言和生成模型。在整体架构上,剂泰的AiLNP和DeepSeek有异曲同工之妙,在通用领域和纳米材料设计领域相映成趣,从应用端证明了强化学习图灵奖的实至名归。
DeepSeek的另一个亮点是将蒸馏模型发扬光大,他们利用R1强大的推理能力做为老师,教学生(小的模型)推理能力,使小模型快速、有效地传承推理能力,证明了蒸馏的有效性,并适可而止,给了大家自主探索的空间。这类模型使大家特别是个人,在自己有限的资源下可以跑起小一点的(蒸馏、量化)大模型,自己设计、完成想要完成的任务,DeepSeek真正起到了大模型的使者和传播者的作用。
DeepSeek的最后一个亮点是,部分绕开CUDA库,直接通过更底层的PTX汇编语言来开发模块,提高了效率,虽然目前还没法撼动强大的CUDA生态护城河,但为未来的开发埋下了伏笔,他们创造的一种绕开欧美技术垄断的可能性就已经足够给人以强大的信心。
推理大模型的盛行给我们药物研发人员提出了一个问题,现在的大模型走的思维链、严密推理路线,越来越接近我们做科研的思路。我们是否应该改变最开始面对大模型的有保留地接受的思路,不故步自封,主动出击寻找大模型最好的落地场景?下一期我们将抛砖引玉,为大家带来大模型和大模型算法在药企的落地思路解析。

